Exercise II: k-Nearest Neighbors (k-NN)¶
k-NN is a simple and useful non-parametric method that is commonly used for both classification and regression. It relies on having some method of calculating distance between data points, and using the the “nearest” observations to predict the target value for new ones.

The Curse of Dimensionality
The curse of dimensionality refers to various phenomena that arise when analyzing and organizing data in high-dimensional spaces that do not occur in low-dimensional settings such as the three-dimensional physical space of everyday experience. Wikipedia
k-NN normally performs better with a limited number of features. In simplified terms, distances become increasingly large in higher dimensionality spaces.
Loading the Dataset¶
In this exercise we will use the Iris Flower Dataset. This dataset is commonly used for demonstrating simple statistical concepts and therefore scikit-learn provides us with a utility function to load it.
import pandas as pd
from sklearn.datasets import load_iris
TARGET_NAME = "class"
# Read a type of dictionary with the dataset as well as some metadata.
iris_dataset = load_iris()
# Read the features and targets.
X = pd.DataFrame(iris_dataset.data, columns=iris_dataset.feature_names)
y = pd.Series(iris_dataset.target, name=TARGET_NAME)
Basic Exploration¶
print(iris_dataset.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
.. topic:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...

import numpy as np
# Set Pandas floating point display precision.
pd.set_option("precision", 2)
# Class colors
COLORS = "rgba(255, 0, 0, 0.3)", "rgba(0, 255, 0, 0.3)", "rgba(0, 0, 255, 0.3)"
# Create a unified dataframe.
data = pd.concat([X, y], axis="columns")
# Set class background color
def set_class_color(class_index: str) -> str:
return f"background-color: {COLORS[class_index]};"
def set_class_name(class_index: str) -> str:
return iris_dataset.target_names[class_index]
# Select some sample indices
sample_indices = np.linspace(0, len(data) - 5, 3, dtype=int)
sample_indices = [index for i in sample_indices for index in range(i, i + 5)]
# Display table
data.iloc[sample_indices, :].style.background_gradient().applymap(
set_class_color,
subset=[TARGET_NAME]).format(set_class_name, subset=[
TARGET_NAME
]).set_properties(**{
"border": "1px solid black"
}, subset=[TARGET_NAME]).set_properties(**{
"text-align": "center"
}).set_table_styles([
dict(selector="th", props=[("font-size", "14px")]),
dict(selector="td", props=[("font-size", "12px")]),
])
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | class | |
|---|---|---|---|---|---|
| 0 | 5.10 | 3.50 | 1.40 | 0.20 | setosa |
| 1 | 4.90 | 3.00 | 1.40 | 0.20 | setosa |
| 2 | 4.70 | 3.20 | 1.30 | 0.20 | setosa |
| 3 | 4.60 | 3.10 | 1.50 | 0.20 | setosa |
| 4 | 5.00 | 3.60 | 1.40 | 0.20 | setosa |
| 72 | 6.30 | 2.50 | 4.90 | 1.50 | versicolor |
| 73 | 6.10 | 2.80 | 4.70 | 1.20 | versicolor |
| 74 | 6.40 | 2.90 | 4.30 | 1.30 | versicolor |
| 75 | 6.60 | 3.00 | 4.40 | 1.40 | versicolor |
| 76 | 6.80 | 2.80 | 4.80 | 1.40 | versicolor |
| 145 | 6.70 | 3.00 | 5.20 | 2.30 | virginica |
| 146 | 6.30 | 2.50 | 5.00 | 1.90 | virginica |
| 147 | 6.50 | 3.00 | 5.20 | 2.00 | virginica |
| 148 | 6.20 | 3.40 | 5.40 | 2.30 | virginica |
| 149 | 5.90 | 3.00 | 5.10 | 1.80 | virginica |
X.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
dtypes: float64(4)
memory usage: 4.8 KB
X.describe()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| count | 150.00 | 150.00 | 150.00 | 150.00 |
| mean | 5.84 | 3.06 | 3.76 | 1.20 |
| std | 0.83 | 0.44 | 1.77 | 0.76 |
| min | 4.30 | 2.00 | 1.00 | 0.10 |
| 25% | 5.10 | 2.80 | 1.60 | 0.30 |
| 50% | 5.80 | 3.00 | 4.35 | 1.30 |
| 75% | 6.40 | 3.30 | 5.10 | 1.80 |
| max | 7.90 | 4.40 | 6.90 | 2.50 |
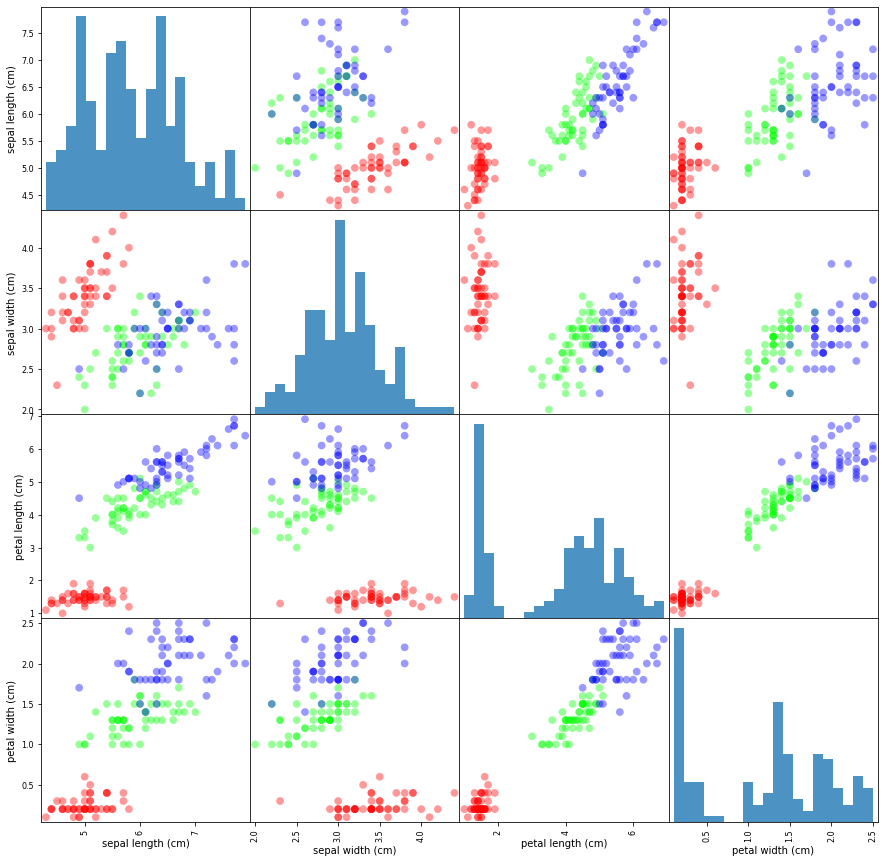
from matplotlib.colors import ListedColormap
cmap = ListedColormap([(1, 0, 0), (0, 1, 0), (0, 0, 1)])
_ = pd.plotting.scatter_matrix(X,
c=y,
cmap=cmap,
figsize=(15, 15),
marker='o',
hist_kwds={
'bins': 20,
'alpha': 0.8
},
s=60,
alpha=0.4)
Train/Test Split¶
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
random_state=0,
test_size=0.25)
We now have a training dataset consisting of 112 observations and a test dataset with 38 observations.
Model Creation¶
from sklearn.neighbors import KNeighborsClassifier
k = 1
knn = KNeighborsClassifier(n_neighbors=k)
_ = knn.fit(X_train, y_train)
Model Evaluation¶
Misclassification Rate / Accuracy¶
import numpy as np
y_predicted = knn.predict(X_test)
misclassification_rate = np.mean(y_predicted != y_test) * 100
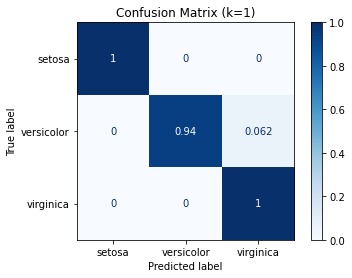
Our model achieved a misclassification_rate of '2.632'%, meaning it correctly predicted 37 of 38 target values in our test set.
Another way to look at it is:
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predicted) * 100
97.36842105263158
Confusion Matrix¶
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_predicted)
array([[13, 0, 0],
[ 0, 15, 1],
[ 0, 0, 9]])
import matplotlib.pyplot as plt
from sklearn.metrics import plot_confusion_matrix
disp = plot_confusion_matrix(knn,
X_test,
y_test,
display_labels=iris_dataset.target_names,
cmap=plt.cm.Blues,
normalize="true")
_ = disp.ax_.set_title(f"Confusion Matrix (k={k})")
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/sklearn/utils/deprecation.py:87: FutureWarning: Function plot_confusion_matrix is deprecated; Function `plot_confusion_matrix` is deprecated in 1.0 and will be removed in 1.2. Use one of the class methods: ConfusionMatrixDisplay.from_predictions or ConfusionMatrixDisplay.from_estimator.
warnings.warn(msg, category=FutureWarning)